Схема работы адаптивного распознавания Рассмотрим подробнее схему, объединяющую оба подхода. Функционирование схемы разделяется на несколько этапов: первичное распознавание, сбор статистики, кластеризация собранной статистики, формирование эталонов (базы характеристик), дораспознавание. Кратко определим каждый из названных этапов. - Первичное распознавание означает распознавание всей страницы с помощью шрифтонезависимого алгоритма. - Сбор статистики подразумевает процесс отбора надежно распознанных символов, которые впоследствии составят обучающую выборку для шрифтозависимого алгоритма. - Кластеризация - разбиение обучающей выборки на кластеры(классы). С помощью такого разбиения уточняются результаты распознавания, полученные на этапе первичного распознавания, будет выявлена статистическая структура страницы, т.е. получен ответ на вопрос: группируются ли одинаковые символы на данной странице, подготовлен исходный материал для обучения шрифтозависимого алгоритма. - Формирование эталонов это создание окончательных, двоичных наборов данных (базы характеристик), по которым будет производиться дораспознавание. - Дораспознавание - второй проход распознавания по всей странице с целью уточнить результаты первичного распознавания, выставить адекватные оценки точности, дораспознать то, что было не распознано ранее, отметить ненадежно распознанные символы. При разработке объединенного метода распознавания прежде всего необходимо определить объем информационной единицы, над которой должен работать метод. Имеется в виду количественная иерархия, а именно: символ, группа символов, слово, строка символов, страница текста, пакет страниц. По следующим причинам был выбран уровень одной страницы текста: - это естественная единица информации, которая существует безотносительно проблематики ОРС; - это достаточно крупная единица, для того чтобы собранная статистика была вполне представительна. Например, количество символов на обычной машинописной странице - 2000, относительная частота буквы "н” в русском языке 0.053; таким образом на странице текста количество букв "н” в среднем составляет 2000 х 0.053 = 106. Этого вполне достаточно для оценки статистических параметров выборки по данной букве, разбиения на классы (кластеризации) и построения двоичных эталонов для дораспознавания. Рассмотрим подробнее этапы, из которых состоит алгоритм адаптивного распознавания символов. Итак, первым этапом является распознавание всей страницы с помощью шрифтонезависимого алгоритма (первичное распознавание). В данном случае не важно, откуда взялся этот алгоритм, каким образом он анализирует символы, его особенности и детали реализации. Предположим, имеется некий готовый шрифтонезависимый алгоритм с заданным качеством распознавания. Все символы, распознанные с надежностью, превышающей заданный порог, считаются материалом для обучения базы характеристик. Важно отметить, что на этапе первичного распознавания нет необходимости добиваться повышения качества распознавания, например за счет усложнения самого алгоритма или отдельного кодирования всех специальных случаев (в которых основной алгоритм работает неудовлетворительно); простота и эффективность основной процедуры алгоритма важнее, чем высокий процент качества или проработка спецслучаев. На практике чрезвычайно полезной является верификация символов-кандидатов в обучающую выборку, т.е. проверка правильности распознавания с помощью независимого метода. Например словарный контроль, частотные двухбуквенные и трехбуквенные сочетания (диады и триады) и т.п. Верификация необходима для того, чтобы снизить количество ошибок в символах, на которых впоследствии будет проводиться обучение. Отсутствие ошибок в обучающей выборке важно, т.к. любая ошибка может привести к формированию ложного эталона распознавания, что в свою очередь приведет к систематической ошибке на этапе дораспознавания. Выше, при перечислении этапов, на которые делится метод адаптивного распознавания, верификация не была выделена в отдельный этап, т.к. в этом методе она не играет принципиальной роли. Кластеризация Необходимость разбиения совокупности объектов на несколько групп нередко возникает в самых разных областях знаний - как, например, классификация различных видов бабочек в биологии или классификация языков Новой Гвинеи в лингвистике. Задачей кластеризации и называется задача расклассификации предъявленных объектов по нескольким группам, причем число групп не обязательно известно. Каждую полученную группу часто называют кластером. Существуют разные математические методы и подходы к решению задачи кластеризации [1]. Одним из методов является метод цепной развертки, кратко опишем его. В этом методе в качестве исходного берется любой объект из предъявленной совокупности , ему приписывается номер 1 и расстояние 0. Затем просматриваются все оставшиеся объекты. Выбирается объект, расстояние от которого до исходного элемента минимально. Ему присваивается номер 2 и расстояние, равное расстоянию до исходного объекта. Затем среди оставшихся ищется объект, расстояние от которого до уже отмеченного множества объектов из двух элементов минимально, и т.д. - всегда на очередном шаге выбирается объект, расстояние от которого до уже пронумерованных объектов ( как расстояние до множества ) минимально, ему приписывается очередной номер и это расстояние. Процедура повторяется пока все объекты не будут пронумерованы. В результате все объекты будут выстроены в некотором порядке, и каждому объекту приписано некоторое число - расстояние до предшествующего множества. Теперь для того, чтобы разделить исходное множество на несколько кластеров таким образом, чтобы расстояние между любыми объектами, входящими в разные кластеры, было больше заданного расстояния d0, а для любых объектов из одного кластера (p1,p2) можно было найти объекты из того же кластера (обозначим их o[1],o[2],..,o[n]) , такие что o[1]=p1, o[n]=p2, и для любого i, i < n расстояние между соседними объектами d(o[i],o[i+1]) не больше d0, достаточно просто просмотреть все приписанные объектам расстояния и пометить те из них, которые больше d0. Пусть это будут номера N1,N2,...,Nk. Тогда к первому кластеру следует отнести все объекты с номерами меньше N1, ко второму все объекты с номерами от N1 до N2 и т.д. После процедуры цепной развертки также легко проводить анализ - при каких значениях порога d0 возникают разные варианты кластеризации, как эти варианты соотносятся между собой и многое другое. Но как легко видеть, данная процедура требует N*(N-1)/2 процедур вычисления расстояния между объектами, если всего имеется N объектов, поэтому бывает необходимо в связи с повышением быстродействия использовать иные приемы. Примером как правило более быстрого варианта кластеризации можно привести модификацию описанного выше метода - кластеризацию с фиксированным порогом. В качестве исходного берется любой символ, ему присваивается принадлежность к первому кластеру. К данному первому кластеру присоединяются все символы, принадлежность которых к какому-либо кластеру еще не установлена, и расстояние от которых до исходного символа меньше порога d0. Затем для каждого из вновь присоединенных символов данная процедура повторяется . После того как к первому кластеру никто не может быть больше отнесен, среди символов, которые остались, берется произвольный символ в качестве затравочного для второго кластера и т.д. пока не будут исчерпаны все символы. В худшем случае и здесь при наличии N символов надо N*(N-1)/2 процедур вычисления расстояния, но в лучшем случае всего N процедур. Конечно, важнейшую роль в кластеризации играет выбранная метрика, т.е. что понимается под расстоянием между объектами. При разном выборе метрики естественно возникают разные варианты кластеризации. Какую метрику использовать применительно к символам? Учитывая то, что к одному и тому же кластеру желательно отнести как хорошо пропечатанные и отсканированные , так и дефектные символы одинакового размера и начертания ( как это сделал бы человек ), кажется естественным прибегнуть к побитовому (поточечному) сравнению растров. Как видно из описания процедуры кластеризации, она может потребовать много операций вычисления расстояний между различными изображениями символов. Поэтому кроме того, что выбранная метрика должна по возможности быть устойчива к различным дефектам изображения ( как уже бывшим в исходном изображении, так и появившимся после сканирования ), метрика должна допускать быстрое вычисление. Если просто подсчитывать число несовпадающих точек в двух разных растрах, то возникает проблема центрирования - смещение даже на один пиксел может вызвать большой скачок при вычислении расстояния. Кроме того, изменение жирности символа всего на один пиксел ( что нередко возникает при сканировании даже текстов хорошего качества, не говоря о текстах плохого качества ) также вызывает большое изменение при вычислении расстояния простым сравнением. Поэтому представляется разумным вычислять расстояние между символами, основываясь на метрике Хаусдорфа. Кратко напомним определение метрики Хаусдорфа. Пусть в некотором пространстве определено расстояние между точками, обозначим его d(x,y). Тогда расстояние от точки x до множества Y d(x,Y) определяется как нижняя грань расстояний d(x,y) для y из Y. Расстояние от множества X до множества Y d1(X,Y) определяется как верхняя грань расстояний d(x,Y) для всех x из X. Расстояние Хаусдорфа между множествами X,Y d(X,Y) определяется как максимум расстояний от X до Y и от Y до X, т.е. d(X,Y)=max(d1(X,Y),d1(Y,X)). Таким образом, разные множества в метрике Хаусдорфа близки, если и только если для любой точки из одного множества в ее малой окрестности содержится хотя бы одна точка другого множества (и то же самое для другого множества). В случае символов можно рассматривать расстояние между символами как расстояние Хаусдорфа между множествами точек, составляющих разные символы. Но необходимо заметить, что вычисление расстояния Хаусдорфа "в лоб" требует слишком много вычислений даже для проверки того, что это расстояние между символами больше или не больше единицы. Для того чтобы проверить все точки растра, надо проверить каждую точку - черная она или белая, т.е. принадлежит символу или нет, и если принадлежит, надо проверить до восьми ее соседей, т.е. при средней заполненности растров на четверть и при размерах растров m на n может потребоваться до 2*(m*n*3/4+m*n*9/4)=6*m*n элементарных операций. Поэтому полезно использовать некоторые приемы для оценки расстояния Хаусдорфа. Для эффективного вычисления расстояния между символами используется следующий прием. Для каждого символа помимо собственно изображения создается растр, в котором кроме исходных точек содержатся также точки окрестности ("размазанное" изображение). После чего вычисление расстояния между символами сводится к простому выявлению пикселов одного растра, которые не вошли в "размазанное" изображение другого символа. Таким образом требуется одна операция для одного байта (для восьми пикселов) растра - исключающее "или", или две операции - если надо узнать и количество пикселов, выходящих за рамки единичной (или иной) окрестности. Следовательно надо не больше 2*(m*n*2/8)=m*n/2 элементарных операций.
Рассмотрим этап создания базы эталонных характеристик. Эталонными характеристиками называются различные признаки символов, которые измеряются и/или вычисляются по символам из обучающей выборки. Базой характеристик называется список всех характеристик в виде готовом к распознаванию (обычно это двоичное представление), плюс система адресации или быстрого поиска в этом списке. Конкретный набор характеристик и способы их вычисления собственно и определяют некий алгоритм распознавания. Однако в данном случае нас не интересует какой-либо конкретный алгоритм. Ниже следует подробное описание формы, в которой эталоны хранятся в базе характеристик. Один эталон соответствует одному кластеру, получившемуся в процессе кластеризации. Напомним, что кластер состоит из набора битовых растров символов, которые попали в этот кластер. Будем называть пиксел растра черным, если он принадлежит символу и белым, если фону изображения. Итак, на растровую сетку фиксированного размера Wmax x Hmax положим все растры символов (соответственно отцентрированные) и просуммируем внутри каждой ячейки. В соответствующую ячейку кластера запишем сумму (количество раз, которое в этой ячейке встретился черный пиксел). Очевидно, что это число является частотой или, если его нормировать на количество символов в кластере, вероятностью появления пиксела в этой ячейке. Ячейки, в которых вероятность равна нулю, заполняются по другому. Туда записывается расстояние до ближайшей точки с ненулевой вероятностью. Это расстояние будет трактоваться как "отрицательная вероятность” появления пиксела в этой ячейке. Таким решением модели придается симметричность, что, как будет показано впоследствии, упростит вычисление оценки точности распознавания. Кроме того это позволяет избежать напрасного расхода компьютерной памяти, которая выделена под все ячейки вне зависимости попадает в них что либо или нет. Само расстояние можно считать в различных метрических системах, например, как расстояние в евклидовом пространстве. Однако в последнем случае присутствует извлечение квадратного корня, что накладывает дополнительные условия: операции с числами в формате плавающей запятой и, что гораздо существенней, многократный вызов самой процедуры вычисления корня. Для ускорения операции вычисления расстояния допустимо использовать метрики пространства L1 , например, D(x,y) = x+y или D(x,y) = Max(x,y). Оба способа целочисленны и просты, а их отличия от евклидовой метрики для данной задачи не существенны. Отвлекаясь от деталей, можно сказать, что эталон представляет собой центрированное в некоторой области двухмерное распределение вероятностей появления черных пикселов. Это распределение полностью описывает вероятностную природу класса символов(кластера). Именно эта информация является априорным знанием для этапа дораспознавания. В терминах описанной модели собственно процесс распознавания заключается в получении ответа на вопрос, насколько хорошо конфигурация черных пикселов символа совпадает с распределением данного кластера. Ответ будет получен в виде числа, означающего вероятность того, что поступивший на распознавание символ принадлежит кластеру, по эталону которого ведется распознавание. База характеристик может содержать большое количество информации. Оценим его для средних значений всех параметров: Wmax = 128; Hmax = 64; N - среднее количество кластеров N = 50; Получаем 128 * 64 * 8 * 50 = 3276800 бит = 409600 байт. Как в случае любого крупного массива информации, встает вопрос быстрого поиска нужных данных. Практически это задача построения индекса - одна из основных, возникающих при создании любой СУБД. Точнее говоря, речь идет о создании специальной служебной информации (индекса), которая определяет эффективный способ поиска данных внутри некоторого множества. Эта задача в общем случае (когда природа данных неизвестна) не решена. Применительно к теме работы необходимо сравнивать пришедший для распознавания символ не со всеми имеющимися кластерами, что было бы неэффективно, а с небольшим подмножеством наиболее близких. Наметим только возможные подходы к решению проблемы. Прежде всего ответим на вопрос, каким критериям должен удовлетворять индекс. Очевидно, что основным требованием является эффективное уменьшение количества операций, требуемых для нахождения элемента данных. Затем следует указать компактность (т.е. объем индекса должен быть настолько мал, насколько это возможно) и легкость модификации ( т.е. легкость перестройки индекса при очередном изменении множества данных). Последним критерием можно пренебречь в случае, когда известно, что исходное множество впоследствии не будет подвергаться модификации. Наиболее очевидный способ - исследовать корреляцию между эталонами и по результатам сравнения символа с одним из эталонов принимать решение следует или не следует сравнивать этот символ со следующим эталоном. Другой путь состоит в том, чтобы на этапе обучения вычислять какой-либо признак или набор признаков у всех символов из обучающей выборки. Значение этого признака полагать адресом кластера, в который попал символ с данным значением признака. Далее в процессе распознавания вычислять этот признак у символа, поступившего на распознавание, и сравнивать его только с теми эталонами, которые этот признак адресует. Безусловно, что такой способ выбора подходящих кластеров будет ошибаться, и тем не менее, если процент ошибок не велик, то указанный способ может быть использован, например, в качестве начального шага. При этом в случае неудачи запускается линейный поиск по всем кластерам. Дораспознавание Дораспознавание есть повторный проход по всей странице с целью распознать все, что не распознано на первом проходе и получить для всех символов надежные оценки точности распознавания. При дораспознавании включается в работу шрифтозависимый алгоритм с базой характеристик, настроенной (адаптированной) к символам текущей страницы. Рассмотрим детально процедуру шрифтового распознавания, она очевидно привязана к формату эталона (см. предыдущий раздел). Итак, схема основной процедуры проста. На вход поступил очередной символ, требующий распознавания; он представлен в форме битового растра. Сравнивая этот символ с первым эталоном (кластером), получаем численную оценку сходства символа с эталоном. Повторяем сравнение со всеми остальными эталонами в базе. После этого выбираются несколько наилучших ответов в соответствии с полученными оценками. Рассмотрим правила, по которым осуществляется само сравнение растра с эталоном. Сначала минимальный охватывающий прямоугольник символа центрируется относительно сетки эталона. Далее предполагается, что центр символа и центр эталона точно совмещены. Проблемы и ошибки, возникающие при центрировании, будут обсуждены ниже. Затем вычисляется сумма вероятностей по всем точкам эталона, соответствующим черным пикселам растра символа. Далее полученная сумма нормируется, (т.е. приводится к обычной шкале вероятностей от 0 до 1) и умножается на масштабный коэффициент. Математическая запись для процесса вычисления оценки сравнения растра с эталоном имеет следующий вид: 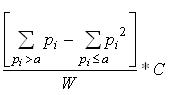
где pi ке эталона W - нормирующий коэффициент С - масштабный коэффициент a - порог, управляющий точностью Из формулы видно, что влияние точек с "отрицательными вероятностями” на результат усилено; т.е. точки символа, лежащие на расстоянии a и более от положительных, существенно уменьшают общую оценку. Таким образом, в случае, если символ существенно отличается от эталона он гарантированно не получит высокую оценку точности распознавания. Обратимся к функции порога а. Этот порог отмечает то значение вероятности, о котором можно уверенно сказать, что оно указывает на то, что в данную ячейку черные пикселы попадать не должны. Фактически порог нужно устанавливать на первое целое число, большее по модулю, чем суммарная погрешность, возникающая при создании эталона и совмещении эталона с символом. Например, в случае, если все операции проводятся с точностью 1-1,5 пиксела, то порог можно установить равным -2 (минус двум). Таким образом, манипулируя порогом, можно менять "строгость” формулы. В качестве нормирующего коэффициента следует брать сумму вероятностей по всем положительным ячейкам. Полученная таким нормированием оценка не является вероятностью в строгом смысле этого слова по нескольким причинам, в частности, потому что "отрицательные вероятности” в ячейках эталона являются искусственными. Однако такая оценка отвечает интуитивному представлению о мере близости и хорошо зарекомендовала себя на практике. Масштабный коэффициент присутствует в формуле для удобства работы с результатом. Он переводит результат в стандартный для системы числовой интервал. В общем случае он может быть опущен. Вернемся к проблеме центровки символа при наложении его на сетку эталона. Наиболее широко употребляемым и самым простым способом центровки является совмещение геометрических центров сетки и охватывающего прямоугольника символа. Фактически такой способ сам по себе работает неудовлетворительно и при практическом использовании он дополняется возможностью накладывать объекты не только по центрам, но и по небольшим их окрестностям с последующим выбором наилучшего результата. Среди других способов совмещения следует упомянуть совмещение по центрам тяжести и совмещение по осям медианы. К сожалению оба способа также обладают недостатками. Вычисление центра тяжести дает большие погрешности по причине того, что в растре все пикселы имеют равные веса. Совмещение по осям медианы работает хорошо только на объектах типа "пятно”, т.е. на связных объектах, у которых нет различного рода сужений и перешейков. Для большинства букв это условие не выполняется, таким образом этот метод имеет весьма ограниченные возможности применения. Вообще, можно сказать, что проблема нахождения реперных точек, точно описывающих положение растра, еще только ожидает своего решения. Существует еще один аспект, который следует отнести к области дораспознавания. Его можно определить как взаимодействие между двумя независимыми проходами распознавания. Проблема заключается в следующем: после первого прохода (первичного распознавания) страница некоторым образом распознана. Затем на этапе дораспознавания возникает ситуация, когда два алгоритма по разному распознают один и тот же символ. Проблема усугубляется в случа е разрезания/склеивания, когда оба алгоритма предлагают разные цепочки символов. Иными словами встает вопрос о схеме, которая разрешает конфликты между разными этапами распознавания. Очевидно, что основное требование к такой схеме заключается в том, что она с одной стороны не должна ухудшать результаты распознавания, полученные на первом проходе, а с другой стороны должна максимально использовать потенциал второго этапа. Детали функционирования такой схемы сильно зависят от особенностей алгоритмов, генерирующих распознанный текст. Однако в ней существуют части, не зависящие от конкретных внешних факторов. Фундаментом схемы является процедура разбиения входного потока символов на взаимно не перекрывающиеся (в геометрическом смысле) цепочки. Такая цепочка может содержать от одного символа до целого слова. В данном случае предполагается, что пробел всегда разделяет соседние слова. Разбиение на не перекрывающиеся и тем самым независимые цепочки (блоки) позволяет впоследствии однозначно разрешать все конфликты на уровне одной цепочки. Схема функционирует следующим образом: получает очередное слово, проверяет правильность распознавания и уточняет оценки. Если есть подозрение, что хотя бы одна буква распознана не верно - все слово отправляется на перераспознавание шрифтозависимым алгоритмом. Затем слово разбивается на цепочки, а это всегда можно сделать по определению цепочки. И на уровне каждой цепочки решается вопрос: результат какого из этапов, первичного распознавания или дораспознавания, лучше. Существует целый спек
Рекомендую Вам также почитать:
Загрузить, скачать Распознование, Адаптивное распознавание символов Часть 2 бесплатно.
Скачать Адаптивное распознавание символов Часть 2 бесплатно
Адаптивное распознавание символов Часть 2 бесплатно и без регистрации. При копировании материала указывайте источник
Адаптивное распознавание символов Часть 2 download free
|
 Записки сисадмина
Записки сисадмина




